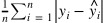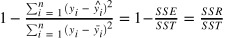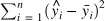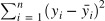종속변수 y 와 한개 이상의 독립변수 X와의 선형 상관관계를 모델링 하는 회기분석(예측) 기법. 오류를 최소화 하거나 가능한 작게 만드는것
종속변수 y = Response 변수, Label, Target
독립변수 X = Predictor, Explanatory, feature (주로 Matrix라서 대문자 X)
선형회귀를 사용하는 목적
Data값 예측 선형 회귀를 사용해 데이터에 적합한 예측 모형을 개발한다. 개발한 선형 회귀식을 사용해 y가 없는 x값에 대해 y를 예측하기 위해 사용할 수 있다.
Data간의 관계 예측 종속 변수y와 이것과 연관된 독립 변수X1, ...,Xp가 존재하는 경우에, 선형 회귀 분석을 사용해Xj와y의 관계를 정량화할 수 있다.Xj는 y와 전혀 관계가 없을 수도 있고, 추가적인 정보를 제공하는 변수일 수도 있다.
기준모델 (Baseline Model)
예측모델을 만들기전 간단하면서 직과적으로 최소한의 성능을 나타내는 기준이 되는 모델 (주로 평균값을 이용해 기준모델을 만들어서 이를 평균기준 모델이라고 한다.)
일반적으로최소자승법(least square method)을 사용해 선형 회귀 모델을 세운다. 따라서 문제별로 그에 맞는 기준모델을 설정한다.
분류문제: 타겟의 최빈 클래스 (mode)
회귀문제: 타겟의 평균값 (mean)
시계열회귀문제: 이전 타임스탬프의 값
Scikit-learn에서 선형회귀 process 순서
문제를 풀기에 적합한 모델 선택. 데이터프레임의 클래스, 속성, 하이퍼파라미터를 확인
데이터 준비
fit()메소드 이용 모델 학습 시키기 (scikit-learn)
predict() 메소드를 이용 새로운 데이터를 예측
회귀의 유형조건
독립 변수가 하나: 단순 선형 회귀 (simple linear regression):
독립 변수가 둘 이상: 다중 선형 회귀 (multiple linear regression)
독립 변수와 종속 변수가 선형 관계가 아닌 경우: Polynomial regression, Generalized Additive Model (GAM)
오차항의 확률분포가 정규분포가 아닌 경우: Generalized Linear Model (GLM)
오차항에 자기 상관성이 있는 경우: Auto-regression
데이터에 아웃라이어가 있는 경우: Robust regression, Quantile regression
독립변수 간에 상관성이 있는 경우(다중공선성): Ridge regression, Lasso regression, Elastic Net regression, Principal Component Regression (PCR), Partial Least Square (PLS) regression
- 일변량(Univariate)
- 오직 하나의 양적 독립변수(설명변수)
- 다변량(Multivariate)
- 두 개 이상의 양적 독립변수(설명변수)
- 단순(Simple)
- 오직 하나의 종속변수(반응변수)
- 다중(Multiple)
- 두 개 이상의 종속변수(반응변수)
- 선형(Linear)
- 데이터에 대하여 가능한 변환을 취한 후, 모든 계수들이 방정식에 선형적으로 삽입되어 있음.
- 비선형(Nonlinear)
- 종속변수(반응변수)와 일부 독립변수들의 관계가 비선형이거나 일부 계수들이 비선형적으로 나타남. 계수들을 선형적으로 나타나게 하는 어떤 변환도 가능하지 않음.
- 분산분석(ANOVA)
- 모든 독립변수들이 질적 변수임.
- 공분산분석(ANCOVA)
- 어떤 독립변수들은 양적변수이고 다른 독립변수들은 질적변수임.
- 로지스틱(Logistic)
- 종속변수(반응변수)가 질적변수임.
단순선형회귀 (Simple linear regression)
단순선형 회귀모델을 만들기 위한 좋은 특성을 선택하기 위해 아래와 같은 사항들을 만족 해야한다. 1. 선형성 : 예측하고자 하는 종속변수y와 독립변수X 사이의 선형성을 만족해야하다. (만약 선형하지 않은 변수로 선형호귀분석을 시도할 경우 유의하지 않은 pvalue가 나온다.) 2. 잔차의 등분산성 : 잔차가 등분산성을 만족하지 않은경우, 매우 주요한 변수가 데이터에 추가되지 않고 빠져있다고 해석할 수 있다.잔차의 3. 정규성 : 이는 곧 잔차가 정규분포를 띄는지 여부를 의미하며 이는 유의하지 않은 데이터가 된다.
scikit-learn 라이브러리에서 사용할 예측 모델 클래스 import.
from sklearn.linear_model import LinearRegression