정규화 선형회귀(Regularized Method, Penalized Method, Contrained Least Squares)
정규화(Regularized) 선형회귀 방법은 선형회귀 계수(weight)에 대한 제약 조건을 추가함으로써 모형의 과적합을 막는 방법이다.
모형이 과도하게 최적화되면 모형 계수의 크기도 과도하게 증가하는 경향이 나타난다. 따라서 정규화 방법에서 추가하는 제약 조건은 일반적으로 계수의 크기를 제한하는 방법을 사용한다.
- Ridge 회귀모형
- Lasso 회귀모형
- Elastic Net 회귀모형
Ridge Regression (릿지 회귀, L2 Regression)
Ridge 회귀는 과적합을 줄이기 위해서 사용하는 것, 정규화의 강도를 조절해주는 패널티값인 람다로 모델을 변형하여 과적합을 완화해 일반화 성능을 높여주기 위한 기법
즉, Ridge 회귀는 이 Bias(편향)를 조금 더하고, Variance(분산)를 줄이는 방법으로 Regularization(정규화)를 수행한다.
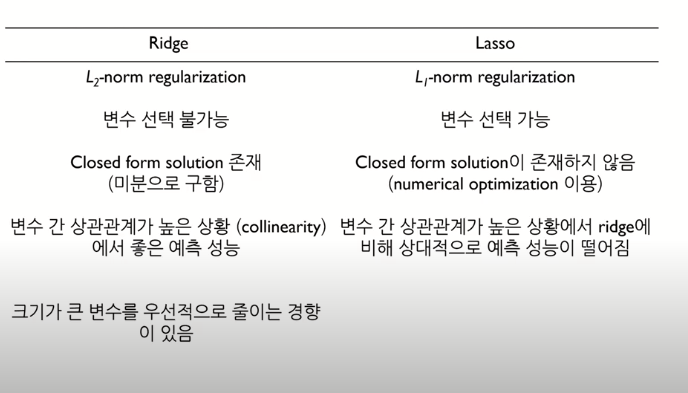
Ridge 회귀모형에서는 가중치들의 제곱합(squared sum of weights)을 최소화하는 것을 추가적인 제약 조건으로 한다.
과적합을 줄이는 간단한 방법 중 한 가지는 모델의 복잡도를 줄이는 방법. 특성의 갯수를 줄이거나 모델을 단순한 모양으로 적합하는 것.
이 람다값(λ)을 효율적으로 구하기 위해서는 여러 패널티(λ) 값을 가지고 검증실험을 해 보는 방법을 사용. Cross-validation(교차검증)을 사용해 훈련/검증 데이터를 나누어 검증실험을 진행한다.
λ 가 0이 되면 βridge의 값은 βOLS와 같아진다. λ -> 0, βridge -> βOLS
λ 가 무한대로 커질수록 βridge의 값은 0.에 가까워진다. λ -> ∞, βridge -> 0.
== λ가 크면 정규화 정도가 커지고 가중치의 값들이 작아진다.
λ가 작아지면 정규화 정도가 작아지며 λλ 가 0이 되면 일반적인 선형 회귀모형이 된다. 다만 Ridge 회귀 직선의 생김새는 OLS매우 비슷하지만 이상치(outlier) 영향을 덜 받는다.
RidgeCV를 통한 최적 패널티(alpha, lambda) 검증
from sklearn.linear_model import Ridge
from sklearn.linear_model import RidgeCV
alphas = [0.01, 0.05, 0.1, 0.2, 1.0, 10.0, 100.0]
ridge = RidgeCV(alphas=alphas, normalize=True, cv=3)
ridge.fit(ans[['x']], ans['y'])
print("alpha: ", ridge.alpha_)
print("best score: ", ridge.best_score_)
alpha: 0.2
best score: 0.4389766255562206왜 최소제곱을 향상시키기 위하여 리지 회귀를 사용할까?
최소제곱 방법보다 리지 회귀가 좋은 점은 bias-variance trade off 때문이다.
λ 가 증가함에 따라, 리지 회귀의 유연성(flexibility)가 감소하고 이것은 분산의 감소를 일으키지만, 편차(bias)를 증가시킨다.
# 한가지 feature로만 릿지회귀
# https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html
for alpha in [0.001, 0.01, 0.1, 1.0, 10.0, 100.0]:
feature = 'sqft_living'
print(f'Ridge Regression, with alpha={alpha}')
model = Ridge(alpha=alpha, normalize=True)
model.fit(X_train[[feature]], y_train)
# Get Test MAE
y_pred = model.predict(X_test[[feature]])
mae = mean_absolute_error(y_test, y_pred)
print(f'Test MAE: ${mae:,.0f}')
train.plot.scatter(feature, target, alpha=0.1)
plt.plot(X_test[feature], y_pred, color='green')
plt.show()# 여러가지 feature로 릿지 회귀
from sklearn.metrics import r2_score
for alpha in [0.001, 0.005, 0.01, 0.02, 0.03, 0.1, 1.0, 1, 100.0, 1000.0]:
print(f'Ridge Regression, alpha={alpha}')
# Ridge 모델 학습
model = Ridge(alpha=alpha, normalize=True)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# MAE for test
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Test MAE: ${mae:,.0f}')
print(f'Test R2: {r2:,.3f}')
# plot coefficients
coefficients = pd.Series(model.coef_, X_train.columns)
plt.figure(figsize=(10,3))
coefficients.sort_values().plot.barh()
plt.show()
Lasso Regression(라쏘 회귀; L1 regression)
가중치의 절대값의 합을 최소화하는 것을 추가적인 제약 조건으로 한다. 라쏘는 제약조건이 절대값이라 아래의 그림처럼 마름모꼴의 형태로 나타납니다. 릿지회귀와 비슷하게 OLS의 RSS 값을 크게 늘려줍니다.