파이썬의 연산자 메소드 연습
def solution(num1, num2): answer = int(num1).__floordiv__(num2) return print(answer) # 연산자 메소드 # __add__(self, other) : + # __sub__(self, other) : - # __mul__(self, other) : * # __truediv__(self, other) : / # __floordiv__(self, other) : // # __mod__(self, other) : % # __pow__(self, other[, modulo]) : ** # __lshift__(self, other) : > ref. https://andamiro25.tistory.com/50 [파이썬]연산자 오버로딩과 특수메소드, Ra..
더보기
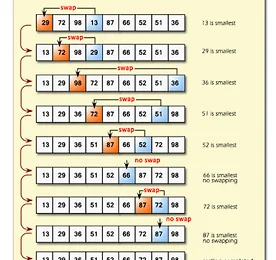 [Computer Science] Iterative Sorting(반복 정렬) - Selection Sort(선택정렬), Insertion Sort(삽입정렬), Bubble Sort(버블정렬), Count Sort (계수 정렬) / 시간 측정 비교
모든 알고리즘의 기본 원리는 숫자와 조건을 활용하면서 발전시킨다고 생각하면, 어려운 알고리즘에 대해 배우는 관점이 달라질 수 있다. Selection Sort(선택정렬) 선택정렬은 가장 작은 노드(최소값)를 선택하고 왼쪽부터 정렬을 하기 위해 알맞은 위치와 교환하는 작업을 반복하는 것. 선택정렬 정리 : 최소노드 선택 -> 왼쪽부터 비교 -> 교환 단점 : 버블정렬과 달리 서로 이웃하지 않은 노드를 교환하므로, 안정적이지 않다. '''선택 정렬 소스 코드 ''' array = [7, 5, 9, 0, 3, 1, 6, 2, 8, 4] for i in range(len(array)): min_index = i #가장 작은 원소의 인덱스로 지정 for j in range(i+1, len(array)): #j는 ..
더보기
[Computer Science] Iterative Sorting(반복 정렬) - Selection Sort(선택정렬), Insertion Sort(삽입정렬), Bubble Sort(버블정렬), Count Sort (계수 정렬) / 시간 측정 비교
모든 알고리즘의 기본 원리는 숫자와 조건을 활용하면서 발전시킨다고 생각하면, 어려운 알고리즘에 대해 배우는 관점이 달라질 수 있다. Selection Sort(선택정렬) 선택정렬은 가장 작은 노드(최소값)를 선택하고 왼쪽부터 정렬을 하기 위해 알맞은 위치와 교환하는 작업을 반복하는 것. 선택정렬 정리 : 최소노드 선택 -> 왼쪽부터 비교 -> 교환 단점 : 버블정렬과 달리 서로 이웃하지 않은 노드를 교환하므로, 안정적이지 않다. '''선택 정렬 소스 코드 ''' array = [7, 5, 9, 0, 3, 1, 6, 2, 8, 4] for i in range(len(array)): min_index = i #가장 작은 원소의 인덱스로 지정 for j in range(i+1, len(array)): #j는 ..
더보기
 [Python] Basic Collection - list[], tuple(), dict{}
기본자료형 vs 컬렉션 자료형 기본 자료형(문자열, 숫자, bool)등은 특정 하나의 값만 사용. 컬렉션은 여러개의 값을 저장 할 수 있다. 컬렉션 자료형의 특징에 따라 리스트, 튜플, 셋, 딕셔너리로 구분. List [ ] 컬렉션 자료형에서 가장 많이 쓰이는 자료형태로; 딘순자료형이 아닌 자료구조의 형태를 취함 리스트는 가변 가능함 (=동적이다) ; 인덱스와 메소드를 활용, 값의 수정 및 정렬이 쉽다. cheeses = ['Cheddar', 'Edam', 'Gouda'] numbers = [123, 456] empty = [] print(cheeses, numbers, empty) # ['Cheddar', 'Edam', 'Gouda'] [123, 456] [] print('numbers[1] :',nu..
더보기
[Python] Basic Collection - list[], tuple(), dict{}
기본자료형 vs 컬렉션 자료형 기본 자료형(문자열, 숫자, bool)등은 특정 하나의 값만 사용. 컬렉션은 여러개의 값을 저장 할 수 있다. 컬렉션 자료형의 특징에 따라 리스트, 튜플, 셋, 딕셔너리로 구분. List [ ] 컬렉션 자료형에서 가장 많이 쓰이는 자료형태로; 딘순자료형이 아닌 자료구조의 형태를 취함 리스트는 가변 가능함 (=동적이다) ; 인덱스와 메소드를 활용, 값의 수정 및 정렬이 쉽다. cheeses = ['Cheddar', 'Edam', 'Gouda'] numbers = [123, 456] empty = [] print(cheeses, numbers, empty) # ['Cheddar', 'Edam', 'Gouda'] [123, 456] [] print('numbers[1] :',nu..
더보기
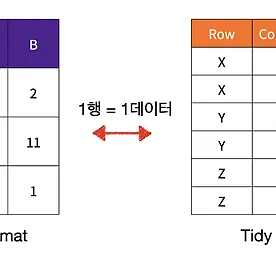 [데이터전처리] tidy-wide tabular data -변환-> Pivot Table, Melt
1. Wide Table (long-form형식) 이러한 데이터를 기반으로 실제로 구현, 변환을 해보겠습니다. %matplotlib inline import pandas as pd import numpy as np import seaborn as sns wide_table1 = pd.DataFrame([[np.nan, 2], [16, 11], [3, 1]], index=['X', 'Y', 'Z'], columns=['A', 'B']) wide_table1 A B X NaN 2 Y 16.0 11 Z 3.0 1 wide_table1은 wide table의 형태 (=long-form) 테이블은 2개의 열과 3개의 행으로 구성되어 있으며 각각 라벨링 되어 있습니다. 2. Transpose (.T; 전치) wid..
더보기
[데이터전처리] tidy-wide tabular data -변환-> Pivot Table, Melt
1. Wide Table (long-form형식) 이러한 데이터를 기반으로 실제로 구현, 변환을 해보겠습니다. %matplotlib inline import pandas as pd import numpy as np import seaborn as sns wide_table1 = pd.DataFrame([[np.nan, 2], [16, 11], [3, 1]], index=['X', 'Y', 'Z'], columns=['A', 'B']) wide_table1 A B X NaN 2 Y 16.0 11 Z 3.0 1 wide_table1은 wide table의 형태 (=long-form) 테이블은 2개의 열과 3개의 행으로 구성되어 있으며 각각 라벨링 되어 있습니다. 2. Transpose (.T; 전치) wid..
더보기





