모델선택(Model selection) 문제
- 우리 문제를 풀기위해 어떤 학습 모델을 사용해야 할 것인지?
- 어떤 하이퍼파라미터를 사용할 것인지?
데이터의 크기에 대한 문제, 모델선택에 대한 문제를 해결하기 위해 사용하는 방법 중 한 가지가 Cross-validation(교차검증).
참고: 교차검증은 시계열(time series) 데이터에는 적합하지 않음.
교차검증을 사용하는 이유는 train/test set로만 나누면 고정된 test set을 가지고 모델의 성능을 확인하고 파라미터를 수정하는 이 과정을 반복하면서 결국 내가 만든 모델은 test set에만 잘 동작하는 모델이되며 이는 Overfitting(과적합)문제를 일으킨다. 이를 해결하기 위해 cross-validationㅇㄹ 사용.
Cross-validation
1. Hold-out Cross-validation(CV)
2. k-fold Ccross-validation(CV)
1. Hold-out Cross-validation
데이터를 훈련/검증/테스트 세트로 나누어 학습을 진행.
2. k-fold cross-validation
교차검증을 하기 위해서 데이터를 k개로 등분, k개의 집합에서 k-1 개의 부분집합을 훈련에 사용하고 나머지 부분집합을 테스트 데이터로 검증하는 방법
예를들어, 데이터를 3등분으로 나누고 검증(1/3)과 훈련세트(2/3)를 총 세번 바꾸어가며 검증하는 것은 3-fold CV. 10-fold CV의 경우 검증을 총 10번하는것.
단점:
훈련세트의 크기가 모델학습에 충분하지 않을 경우 문제 => 학습할 데이터가 많으면 okay
Validation set(검증세트) 크기가 충분히 크지 않다면 예측 성능에 대한 추정이 부정확.
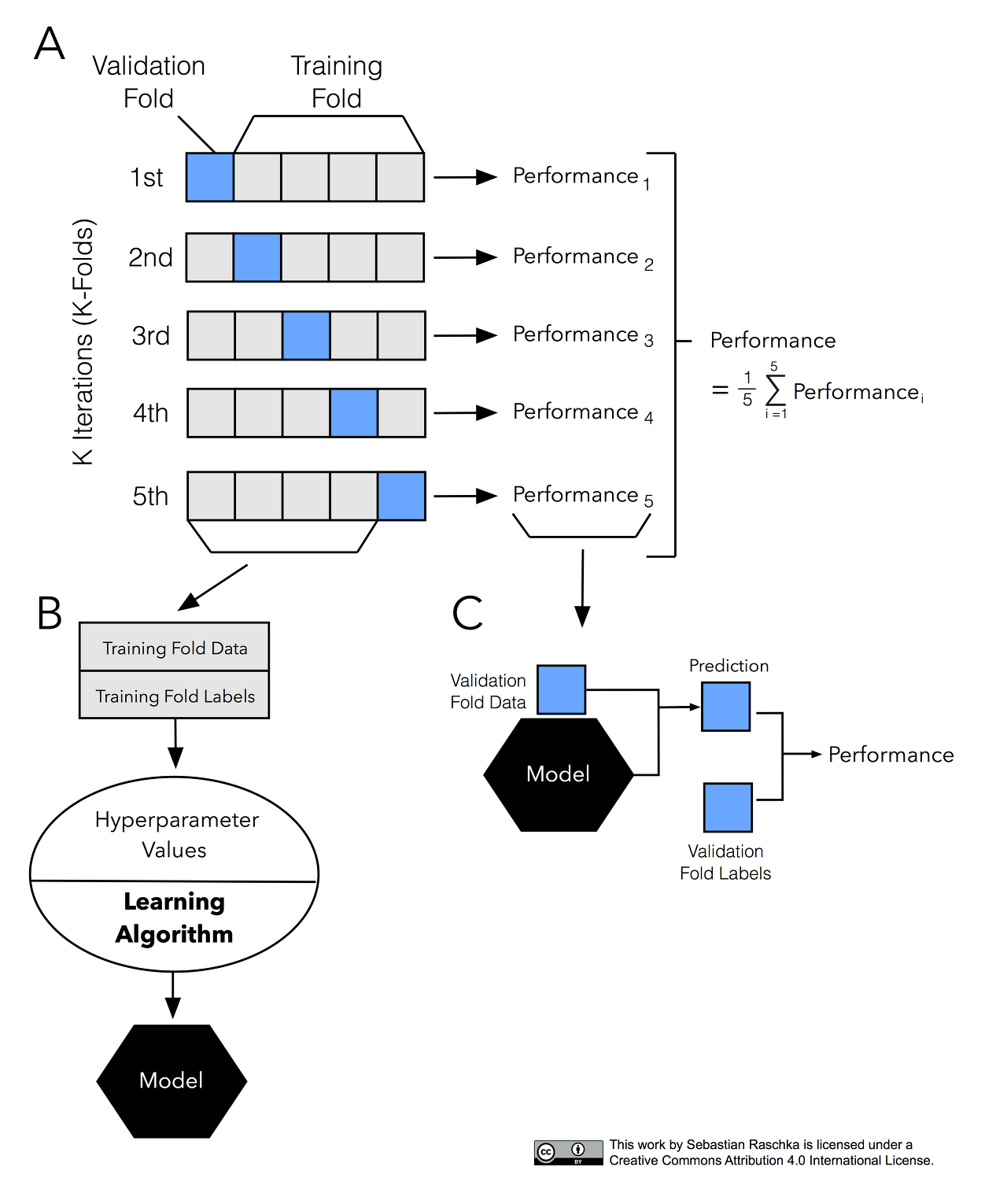
교차 검증 반복자(Cross Validation iterators)
반복자의 선정은 데이터 세트의 모양과 구조에 따라 신중하게 선택이 되어야 합니다. 일반적으로 독립적인지, 동일한 분포인지를 보게 됩니다.
- 데이터가 독립적이고 동일한 분포를 가진 경우
KFold, RepeatedKFold, LeaveOneOut(LOO), LeavePOutLeaveOneOut(LPO) - 동일한 분포가 아닌 경우
StratifiedKFold, RepeatedStratifiedKFold, StratifiedShuffleSplit - 그룹화된 데이터의 경우
GroupKFold, LeaveOneGroupOut, LeavePGroupsOut, GroupShuffleSplit - 시계열 데이터의 경우
TimeSeriesSplit
평가지표
함수는 scoring 매개변수에 원하는 평가 지표를 지정. 분류 문제일 경우 기본은 정확도를 의미하는 ‘accuracy’. 따라서 다음 코드는 위와 동일한 결과를 출력한다.
Python
1. 라이브러리 불러오기
from category_encoders import OneHotEncoder
from sklearn.feature_selection import f_regression, SelectKBest
from sklearn.impute import SimpleImputer
from sklearn.linear_model import Ridge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score# (참고) warning 제거를 위한 코드
np.seterr(divide='ignore', invalid='ignore')2. 데이터의 타겟과 특성 & train/test 로 나누기
target = 'SalePrice'
features = train.columns.drop([target])
X_train = train[features]
y_train = train[target]
X_test = test[features]
y_test = test[target]3. SelectKBest 모델 학습
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(strategy='mean'),
StandardScaler(),
SelectKBest(f_regression, k=20),
Ridge(alpha=1.0))4. cross-validation 수행 평가지표확인
# 3-fold 교차검증을 수행합니다.
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
print(f'MAE ({k} folds):', -scores)MAE (3 folds): [19912.3716215 23214.74205495 18656.29713167]
3-1. Random Forest Regressor 모델 학습
from category_encoders import TargetEncoder
from sklearn.ensemble import RandomForestRegressor
pipe = make_pipeline(
# TargetEncoder: 범주형 변수 인코더로, 타겟값을 특성의 범주별로 평균내어 그 값으로 인코딩
TargetEncoder(min_samples_leaf=1, smoothing=1),
SimpleImputer(strategy='median'),
RandomForestRegressor(max_depth = 10, n_jobs=-1, random_state=2))4-1. Random Forest Regressor 모델 학습의 평가지표
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
print(f'MAE for {k} folds:', -scores)MAE for 3 folds: [16289.34502313 19492.01218055 15273.23000751]



