데이터에 대해 완전히 이해하지 못할 때, 모델을 만들고 평가를 진행했는데 예측100% 가깝게 하는 경우->정보의 누수 의심. 여러 특성을 다루다 보면 데이터를 제대로 파악하지 못하고 아래와 같은 경우가 발생한다.
- 타겟변수 외에 예측 시점에 사용할 수 없는 데이터가 포함되어 학습이 이루어 질 경우
- 훈련데이터와 검증데이터를 완전히 분리하지 못했을 경우
- Feature수가 너무 많은경우
- Target과 동일한 Feature가 있을경우
정보의 누수가 일어나 과적합을 일으키고 실제 테스트 데이터에서 성능이 급격하게 떨어지는 결과를 확인할 수 있다.

문제에 적합한 평가지표를 선택해야 한다.
여러분이 만든 예측모델을 어떻게 평가해야 할까요? 그것은 문제의 상황에 따라 다를것 입니다. 특히 분류 & 회귀 모델의 평가지표는 완전히 다르다!
- Scikit-learn metrics
- 분류(classification) metrics
분류문제에서 타겟 클래스비율이 70% 이상 차이날 경우에는 accuracy만 사용하면 판단을 정확히 할 수 없으므로 정밀도, 재현율, ROC curve, AUC 등을 같이 사용하여야 한다. - 회귀(regression) metrics
Python
Confusion_matrix 확인하기
from sklearn.metrics import plot_confusion_matrix
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
pcm = plot_confusion_matrix(pipe, X_val, y_val,
cmap=plt.cm.Blues,
ax=ax);
plt.title(f'Confusion matrix, n = {len(y_val)}', fontsize=15)Out:
Text(0.5, 1.0, 'Confusion matrix, n = 359')

# confusion_matrix 파라미터 변형 적용
plot = plot_confusion_matrix(clf, # 분류 모델
X_test_scaled, y_test, # 예측 데이터와 예측값의 정답(y_true)
display_labels=label, # 표에 표시할 labels
cmap=plt.cm.Blue, # 컬러맵(plt.cm.Reds, plt.cm.rainbow 등이 있음)
normalize=None) # 'true', 'pred', 'all' 중에서 지정 가능. default=None
plot.ax_.set_title('Confusion Matrix')
plot_confusion_matrix()의 인자 중에서, nomalize='true'로 설정하면 말 그대로 정규화를 할 수 있다. 위에서는 개수로 표현된 값이 좀 더 보기 편하게 퍼센트화 된다.
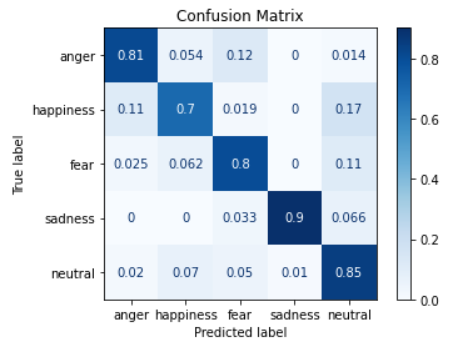
공식 문서를 참고하면, ‘true’는 row 기준, ‘pred’는 column기준으로 정규화 된다고 한다.

Classification Report로 확인 하기
from sklearn.metrics import classification_report
y_pred = pipe.predict(X_val)
print(classification_report(y_val, y_pred)) precision recall f1-score support
False 0.84 0.98 0.91 302
True 0.17 0.02 0.03 57
accuracy 0.83 359
macro avg 0.50 0.50 0.47 359
weighted avg 0.73 0.83 0.77 359ref. https://www.fast.ai/2017/11/13/validation-sets/
How (and why) to create a good validation set · fast.ai
How (and why) to create a good validation set Written: 13 Nov 2017 by Rachel Thomas An all-too-common scenario: a seemingly impressive machine learning model is a complete failure when implemented in production. The fallout includes leaders who are now ske
www.fast.ai



