무작위로 뽑은 하나의 관측값 마다 기울기를 계산하고 바로 가중치를 업데이트 한다.
기존에 사용한 경사하강법은 배치(batch)방법인데, 모든 관측치를 가지고 기울기를 다 계산한 다음에 가중치를 업데이트했었다. 그와 다르게 SGD는 관측치 마다 가중치를 업데이트 하기 때문에 학습이 빠르게 진행되는 장점이 있다.
데이터 샘플이 많아질 수록 SGD가 빠르게 학습이 된다.
단점:
학습 과정 중 손실함수 값이 변동이 심하다.
완화 하는 방법으로 배치방법과 SGD를 합친 Mini-batch 경사하강법을 사용할 수 있다.

경사하강법의 변형들
경사하강법 알고리즘들은 다음과 같습니다.
1) Stochastic Gradient Descent(SGD)
2) SGD의 변형된 알고리즘들(Momentum, RMSProp, Adam 등)
3) Newton's method 등 2차최적화 알고리즘 기반 방법들(BFGS 등)
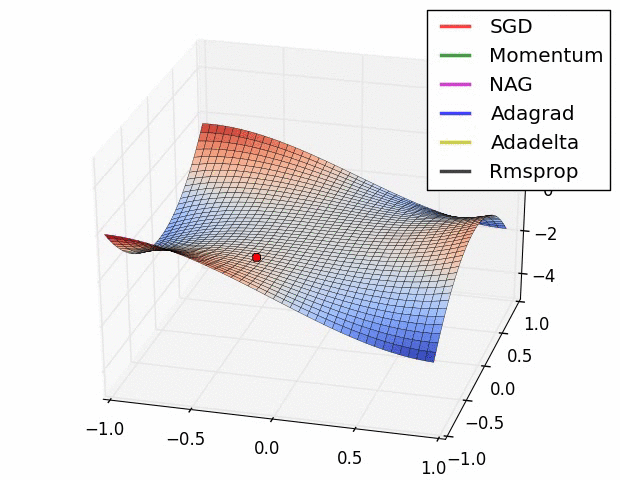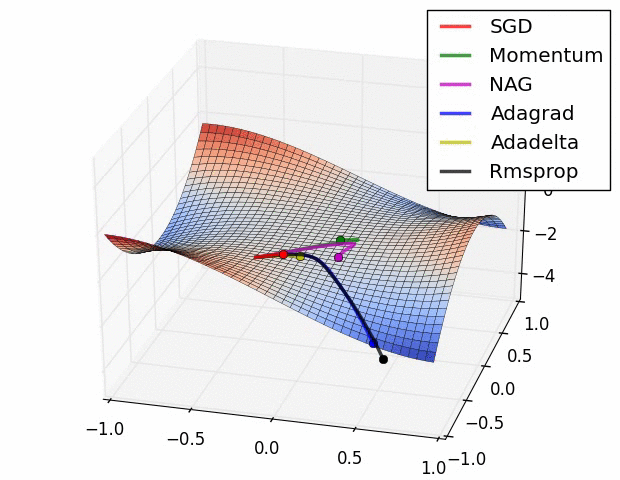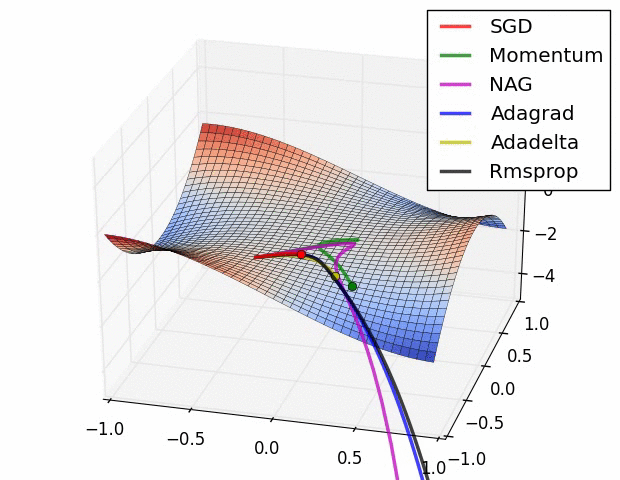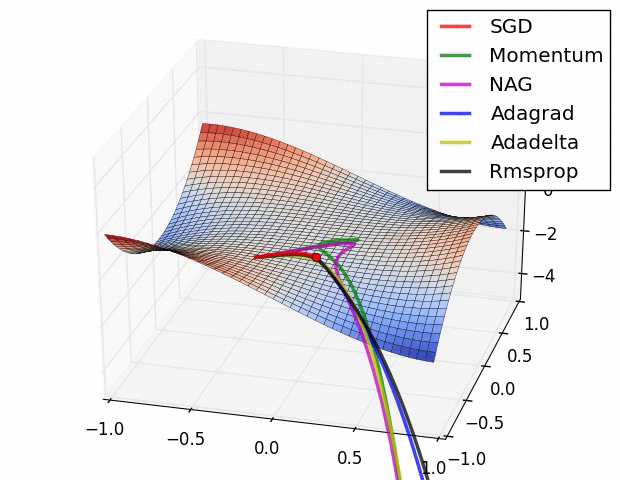
어떤 알고리즘이 우월하다고 말하기는 어려우며, 문제의 종류와 데이터에 따라 결과가 다를 것이므로 여러 알고리즘을 실험해볼 필요가 있다.
텐서플로우 등 머신러닝 라이브러리를 사용하면 쉽게 사용 가능.
Optimizer
Momentum
SGD는 비등산성함수 이기때문에 학습 과정 중 손실함수 값이 변동이 심하다는 문제가 발생한기 때문에 이를 보완하기 위한 Momentum이라는 Optimizer(매개변수 갱신 방법)
모멘텀은 운동량을 의미하며 Momentum Optimizer는 매개변수의 이동에 속도를 부여하는 것을 의미.
쉽게 말해서 구슬을 떨어트리면 급한 경사에서는 더 빨라지듯이 매개변수의 변화에도 속도를 부여하는 것.

또한 SGD가 가지고 있는 또 다른 문제인 Local Minima를 해결 할 수 있다. 모멘텀을 사용한다면 속도의 개념때문에 깊이가 낮은 Local Minima는 위 그림처럼 뛰어넘어 계속 진행 할 수 있다.
ref. https://beoks.tistory.com/30?category=789329
신경망 학습 - (4 - 2) 모멘텀 (Momentum)
신경망 학습 - 4에서는 매개변수를 갱신하는 효율적인 방법에 대해서 알아보겠습니다. 지난번에서는 학습시간을 단축시키기 위해서 미니배치를 추출하여 학습하는 SGD, 확률적 경사하강법에 대
beoks.tistory.com



